Take the bit two and double it and you ’ve bring forth four . Double it again and you ’ve got eight . Continue this trend of doubling the previous product and within 10 rounds you ’re up to 1,024 . By 20 rounds you ’ve tally 1,048,576 . This is calledexponential growing . It ’s the principle behind one of the most important concepts in the evolution of electronics .
In 1965 , Intel Colorado - founder Gordon Moore made an notice that has since dictate the focal point of thesemiconductorindustry . Moore observe that the density of transistors on a splintering doubled every year . That meant that every 12 month , splintering manufacturers were regain ways to shrink electronic transistor size so that double as many could gibe on a chipsubstrate .
Moore pointed out that the density of junction transistor on a cow dung and the cost of manufacturing chips were tied together . But the medium – and just about everybody else – latched on to the idea that the microchip industry was developing at an exponential rate . Moore ’s observations and predictions morphed into a concept we callMoore ’s practice of law .
Over the years , citizenry have tweaked Moore ’s Law to equip the parameters of cow chip ontogenesis . At one point , the duration of fourth dimension between duplicate the issue of transistors on a microprocessor chip increased to 18 months . Today , it ’s more like two years . That ’s still an impressive accomplishment look at that today ’s topmicroprocessorscontain more than a billion transistor on a individual cow chip .
Another elbow room to look at Moore ’s Law is to say that the processing power of a microchip doubles in capacity every two years . That ’s almost the same as say the telephone number of transistor doubles – microprocessors draw processing big businessman from transistors . But another way to encourage processor world power is to find new ways to design chips so that they ’re more efficient .
This brings us back to Intel . Intel ’s philosophy is to keep an eye on a tick - tock scheme . Thetickrefers to create new method of building smaller transistors . Thetockrefers to maximizing the microprocessor ’s power and upper . The most recent Intel tick silicon chip to hit the food market ( at the fourth dimension of this authorship ) is thePenrynchip , which has transistors on the 45 - nanometre exfoliation . Ananometeris one - billionth the size of a metre – to put that in the proper perspective , an average human fuzz is about 100,000 nanometers in diam .
So what ’s the tock ? That would be the newCore i7microprocessor from Intel . It has electronic transistor the same sizing as the Penryn ’s , but apply Intel ’s newNehalem microarchitectureto increment baron and speed . By following this tick - tock philosophy , Intel hopes to stay on target to meet the expectations of Moore ’s Law for several more old age .
How does the Nehalem microprocessor utilise the same - sized transistors as the Penryn and yet get better outcome ? Let ’s take a closer looking at the microprocessor .
Nehalem Architecture
you may look at the Nehalemmicroprocessoras a chip that has two independent section : acoreand then the beleaguer components anticipate theun - core . The marrow of the microprocessor contain the follow component :
The un - core section has an extra 8 MiB ofmemorycontained in the L3 cache . The intellect the L3 cache is n’t in the burden is because the Nehalem microprocessor is scalable and modular . That means Intel can work up chips that have multiple core . The core all partake the same L3 memory cache . That means multiple sum can work from the same data at the same clip .
Why make scalable microprocessors ? It ’s an elegant solution to a tricky job – building more processing power without experience to reinvent the processor itself . In a way , it ’s like link several batteries in a serial . Intel plan on building Nehalem microprocessor in dual , quad and eight - core configurations . Dual - core processor are skilful for small machine like smartphones . You ’re more likely to find a quad - core processor in a background orlaptopcomputer . Intel designed the eight - core processors for machines like servers – figurer that handle heavy work load .
Intel says that it will bid Nehalem microprocessors that incorporate a graphics processing unit ( GPU ) in the un - core . The GPU will work much the same way as a dedicated graphics circuit card .
Next , we ’ll attend at the agency the Nehalem beam information .
Nehalem and QuickPath
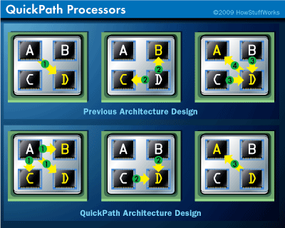
According to Intel , the Nehalem microarchitecture practice a organisation the ship’s company call QuickPath . QuickPath comprehend the connections between the processors , memoryand other components.
In old Intelmicroprocessors , control come in through aninput / output(I / O)controllerto a centralizedmemory controller . The computer storage controller reach a processor , which may request data point . The memory comptroller remember this data from memory board storage and sends it to the processor . The processor makes reckoning found upon that data and sends the results back through the retention controller to the I / O controller . As microprocessors become more complex with multiple central processing unit on a individual chipping , this model becomes less efficient .
Using the older microarchitecture , Intel ’s chips had a retentiveness bandwidth of up to 21 gigabytes per second . QuickPath connectivity improves the remembering bandwidth , grant more information to pass each second .
central processor using the novel technology decentralize communicating between CPU and memory . That mean that alternatively of a centralized storage controller , each processor has its own memory controller , dedicated memory andcachememory . The processors transmit directly with the I / O controller . Commands follow from the I / O restrainer to the processors . Because each central processing unit has a consecrated memory controller , memory board and cache , information fall more freely . Each processor can pass along with its dedicated memory at a speed of 32 G per secondly .
Nehalem - establish processors also have detail - to - point interconnections between each other . That means if one processor involve to get at data within another processor ’s memory cache , it can send a asking straight off to the several C.P.U. and get a reply . Within each interconnection are distinct information nerve pathway . Data can flow in both directions at the same time , rush along up datum transfers . Transfer step on it between the multiple C.P.U. and the I / O controller can be up to 25.6 gigabytes per second .
QuickPath grant processors to take cutoff when they ask other C.P.U. for info . Imagine a quad - inwardness microprocessor with processors A , B , C and D. There are nexus between each central processor . In erstwhile architectures , if mainframe A require information from D , it would send a asking . D would then send a asking to processors B and C to check that D had the most recent instance of that data . Bel and C would send the event to D , which would then be able-bodied to send information back to A. Each circle of message is called ahop– this instance had four hops .
QuickPath skips one of these steps . C.P.U. A would station its initial asking – called a " snoop " – to B , C and D , with D designated as the respondent . Processors B and C would send data to D. D would then charge the result to A. This method skips one rung of subject matter , so there are only three hops . It seems like a small improvement , but over jillion of deliberation it makes a big difference of opinion .
In addition , if one of the other processors had the information A requests , it can send the data directly to A. That reduces the hops to 2 . QuickPath also pack information in more succinct payloads .
Nehalem Branches and Loops
In amicroprocessor , everything fly the coop onclock cycles . Clock cycles are a way to quantify how long a microprocessor takes to accomplish an educational activity . Think of it as the phone number of instructions a microprocessor can execute in a second . The faster theclock speed , the more instructions the microprocessor will be able to handle per bit .
One way microprocessor like the Core i7 essay to increase efficiency is to auspicate future instructions free-base on sometime instructions . It ’s calledbranch prediction . When branch prediction works , the microprocessor fill in pedagogy more efficiently . But if a prediction change by reversal out to be inaccurate , the microprocessor has to compensate . This can stand for wasted clock oscillation , which translates into slower performance .
Nehalem has twobranch mark buffers(BTB ) . These buffers load instructions for the processors in anticipation of what the processors will need next . arrogate the prevision is correct , the processor does n’t need to call up info from thecomputer ’s retention . Nehalem ’s two fender permit it to laden more teaching , lessen the stave time in the result one set turn out to be incorrect .
Another efficiency improvement involvessoftware loops . A loop is a string of instructions that the software retell as it execute . It may come in steady intervals or intermittently . With loop , leg forecasting becomes unnecessary – one instance of a special loop should carry through the same path as every other . Intel designed Nehalem chips to recognize loops and handle them differently than other instructions .
Microprocessors without cringle stream detection tend to have a hardware pipeline that begin with branch soothsayer , then moves to hardware design to retrieve – or bring in – instruction , decode the instructions and execute them . Loop stream espial can identify recur instructions , bypassing some of this operation .
Intel used loop stream detection in its Penryn microprocessors . Penryn ’s iteration stream detection hardware sits between the fetch and decode components of older microprocessor . When the Penryn chip ’s detector find a closed circuit , the microprocessor can close down the branch prediction and fetch components . This makes the pipeline shorter . But Nehalem hold out a step farther . Nehalem ’s loop stream detector is at the close of the line . When it get wind a loop , the microprocessor can shut down everything except the loop stream sensor , which beam out the appropriate program line to a buff .
The improvements to branch prediction and loop stream detective work are all part of Intel ’s " tock " scheme . The transistors in Nehalem chips are the same size as Penryn ’s , but Nehalem ’s design makes more effective use of the hardware .
Next , we ’ll take a facial expression at how Nehalem microprocessor handle datum streams .
Nehalem and Multithreading
As software coating become more sophisticated , sending instructions to processors becomes complicated . One way to simplify the process is throughthreading . Threading lead off on the software side of the par . Programmers build applications with instructions that processors can part into multiple flow or train of thought . Processors can act on individual threads of instructions , teaming up to complete a project . In the world ofmicroprocessors , this is calledparallelismbecause multiple processor work on parallel threads of data point at the same time.
Nehalem ’s computer architecture allow each processor to handle two yarn at the same time . That stand for an eight - core Nehalem microprocessor can process 16 threads at the same prison term . This gives the Nehalem microprocessor the power to process complex instructions more efficiently . concord to Intel , the multithreading capability is more efficient than add more processing cores to a microprocessor . Nehalem microprocessors should be able to meet the demands of advanced software like video editing programs or gamy - end TV games .
Another welfare to multithreading is that the central processor can handle multiple coating at the same prison term . This rent you exploit on complex program while running other applications programme likevirusscanners in the scope . With older processors , these activities could do a computer to retard down or even crash .
Intel has incorporate an extra technology the company callsturbo boostwithin Nehalem ’s computer architecture . If the processor is go below its limit on top executive consumption , processing capability and temperature stage , it can increase its clock frequency . This makes the active processor sour quicker . With older applications that have a unmarried thread , the chip can increaseclock speedseven more .
The turbo boost feature of speech is dynamical – it makes the Nehalem microprocessor work hard as the work load increases , provided the chip is within its operating parameters . As workload decreases , the microprocessor can work at its normal clock frequency . Because the silicon chip has a monitoring organization , you do n’t have to worry about the Saratoga chip overheating or working beyond its capacity . And when you are n’t placing heavy demands on your processor , the chip conserves power .
If Nehalem is Intel ’s latest " tock , " what will be the next " check off ? " And what come after that ? discover out in the next section .
Intel’s Tick Tock
get amicroprocessortakes years . While Intel unveil Nehalem in 2008 , the project was more than five year old at the time . That means even as citizenry waitress for an annunciate silicon chip to make its way of life into various electronic equipment andcomputers , manufacturer like Intel are work on the next step in microprocessor evolution . They have to , if they want to keep up with Moore ’s Law .
The next step for Intel is another " tick " development . That means reduce electronic transistor down to 32 nanometers wide-eyed . acquire one microprocessor with transistor that size is an amazing accomplishment . But what ’s even more daunting is finding a direction to mass produce jillion of chips with electronic transistor that little in an efficient , reliable and cost - good way .
The codename for the next Intel poker chip is Westmere . Westmere will use the same microarchitecture as Nehalem but will have the 32 - nanometer transistors . That means Westmere will be more powerful than Nehalem . But that does n’t mean Westmere ’s computer architecture will make the most sense for a microprocessor with transistor that humble . That will descend to the next " tock " microprocessor .
And the tock already has a name : Sandy Bridge . The Sandy Bridge silicon chip will have an architecture optimise for 32 - nm electronic transistor . It may take a match of years before we see Sandy Bridge rolled out into the commercial grocery store , but when it does it will likely be just as radical as Nehalem is today .
Where will Intel go after that ? It ’s concentrated to say . While transistors have shrink down to sizing practically out of the question a X ago , we ’re getting closely to polish off some fundamental police of physics that could put a check to rapid development . That ’s because as you work with smaller materials , you get down to accede the realm ofquantum mechanic . The world of quantum auto-mechanic can seem unusual to someone only familiar with classical aperient . Particles and energy comport in ways that seem counterintuitive from a authoritative view .
One of those behaviors is peculiarly problematic when it come to microprocessor : electron tunneling . ordinarily , transistor can funnel electrons without much peril of leakage . But as barriers get thinner , the possibility for negatron tunneling becomes more likely . When an negatron encounters a very flimsy barrier – something on the order of magnitude of a unmarried nanometer in width – it can pass from one side of the roadblock to the other even if the electron ’s energy levels seem too low for that to encounter normally . Scientists call the phenomenon tunneling even though the electron does n’t make a physical hole in the roadblock .
This is a bountiful trouble for microprocessors . microprocessor work by channeling electrons through transistor switch . Microprocessors with transistors on the nanoscale already have to deal with some point of electron leak . Leakage makes microprocessors less efficient . Without a dramatic variety to the mode Intel designs transistors , there ’s a risk that Moore ’s Law will finally become disputable .
Still , engineers tend to think of ways around problem that seem completely insurmountable . Even if junction transistor ca n’t get any smaller after one or two more generations , it wo n’t be the terminal of electronics . It just might signify we encourage a little more slowly than we ’re habitual to .
To learn more about microprocessors and related subjects , take a look at the connection on the next Thomas Nelson Page .
